

Episode 2. The World Compiler: A Noitom Robotics Blueprint for the Next Infrastructure Layer of Physical AI
Compared to conventional AI systems, embodied intelligence necessitates a considerably richer and more diverse set of data modalities...
read articleEpisode 1. ModalityNet: The Art of Modalities in Human-Centric Data
Compared to conventional AI systems, embodied intelligence necessitates a considerably richer and more diverse set of data modalities...
read articleEpisode 1. ModalityNet: The Art of Modalities in Human-Centric Data
Introducing ModalityNet
Compared to conventional AI systems, embodied intelligence necessitates a considerably richer and more diverse set of data modalities, encompassing vision, language, motion dynamics, tactile feedback, depth perception, mesh-level object tracking, scene reconstruction, audio signals, and beyond. Such multimodal embodied data are extremely scarce, and even systematic methods for acquisition and collection remain an open research problem.
We propose ModalityNet — https://modalitynet.com, in tribute to the seminal contribution of ImageNet to modern computer vision, aspiring to serve as an embodied intelligence counterpart. ModalityNet is a large-scale human-centric data benchmark that covers various data modalities mentioned above. We first propose a four-level data pyramid structure of embodied AI, which serves as the foundational design principle of ModalityNet.
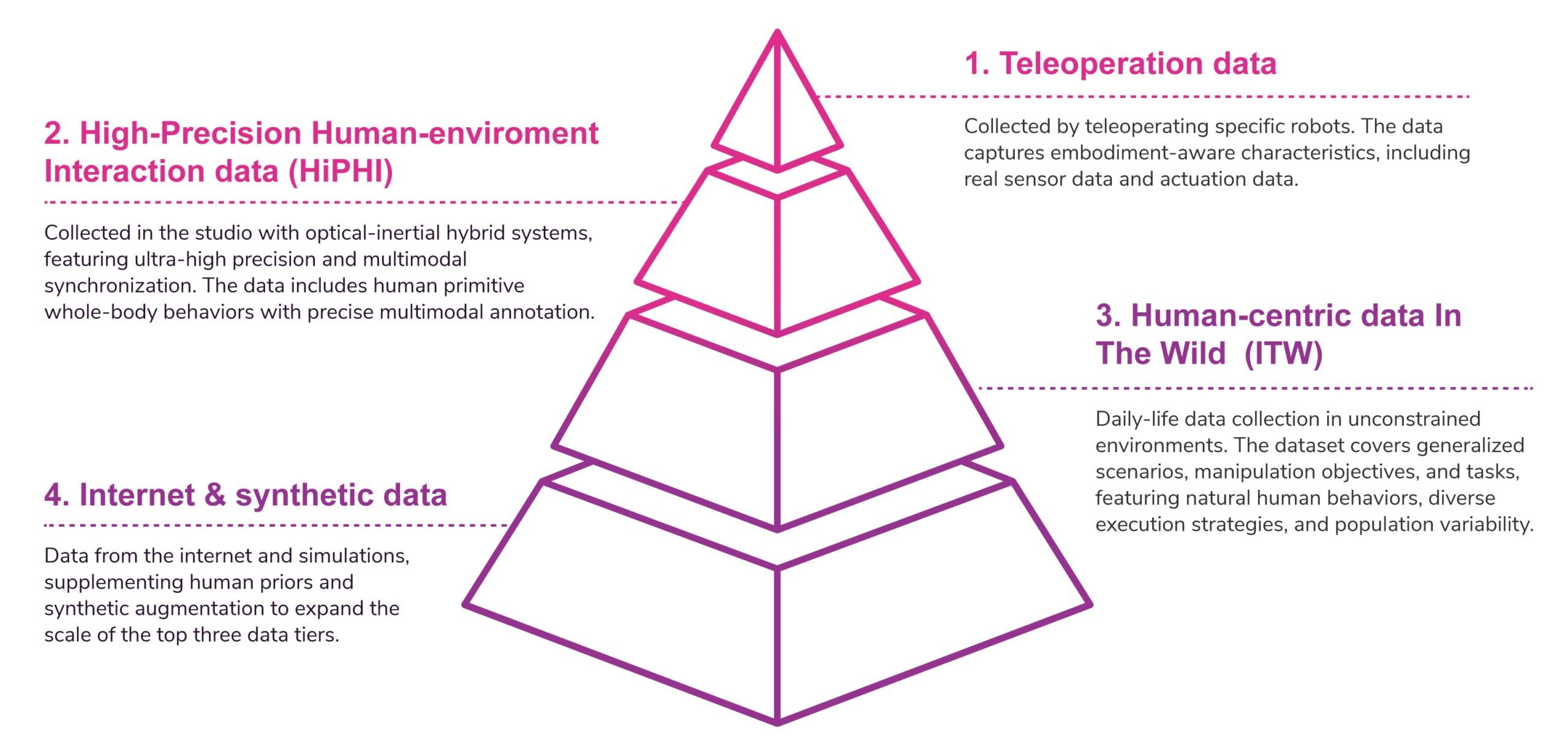
Figure 1
In the data pyramid, as we move from the first layer to the last, the data becomes progressively less embodiment-specific, while its diversity and generalization capability with respect to the real physical world continue scaling up. Teleoperation data offer embodiment-specific and in-domain supervision that policies can be trained via direct behavioral cloning without space gap. However, teleoperation data are expensive and inefficient to collect, and exhibit limited cross-embodiment generalization. Internet data and synthetic data are inherently multi-source and large-scale. They offer substantially greater diversity, but the discrepancy between the data formats and the observation / action space of embodiments is significant, as well as largely unconstrained precision, making direct alignment with embodied control particularly challenging.
To bridge the substantial gap between the top and bottom layers, ModalityNet focuses on the acquisition of two novel categories of human-centric data as intermediate layers that are High-Precision Human-environment Interaction (HiPHI) data and human-centric In The Wild (ITW) data. HiPHI is collected in dedicated data studios, featuring ultra-high precision and multimodal synchronization, while ITW aims at natural diversity from daily-life collection. Specifically, three datasets are defined:
The three datasets are strategically positioned along three orthogonal design dimensions of embodied data. HiPHI-MOV spans the motion space, HiPHI-OM captures full-spectrum multimodality, and ITW grounds the intrinsic complexity of real-world distribution. Below, we introduce each dataset in detail.
The HiPHI-MOV Data
Introduction
The HiPHI-MOV Dataset is a human-centric, high-fidelity multimodal corpus specifically engineered for the development of robust locomotion and whole-body loco-manipulation policies. It includes full-body motion capture, tracking of interacting objects if present, and sideview RGB-D data. Full-body motion is modeled and output as a body BVH file with 21 end-effector 6-DOF poses. The entire acquisition environment is deployed within large studios with hybrid optical-inertial motion capture systems.
HiPHI-MOV is intentionally designed for whole-body behavior, with palm-level loco-manipulation tasks. The manipulated objects are relatively larger items, such as tables, chairs and boxes. Fine-grained and dexterous finger-level manipulation is systematically studied in the HiPHI-OM dataset. There are two examples shown below, and more instances can be previewed on the webpage.
Video 1
Quality Assessment
As described above, HiPHI-MOV aims to span whole-body motion space. To achieve this, we employ a set of embodiment-relevant verb primitives guided by the FrameNet [1] theory to cover the entire human whole-body motion space. For each primitive, we guide LLMs to generate performance scripts for data collection. Under this script-generation framework, the dataset structure is organized as illustrated in Figure 2 and performed by hundreds of actors of diverse body shapes and heights.
A certain portion of motion primitives correspond to human self-motion that does not involve object interaction, and recent advances, such as NVIDIA's SONIC [2], have been trained on hundreds of hours of large-scale mocap data of this kind. Another substantial portion of motion primitives in our framework involve full-body interactions with objects. For these primitives, we simultaneously capture mesh-level object trajectories. HiPHI-MOV is intentionally designed for whole-body behavior.
We evaluate multiple quality dimensions of HiPHI-MOV data, including mesh penetration, floating artifacts, skating, and other physical inconsistencies. We compare HiPHI-MOV with several of the most influential motion datasets in the field, including AMASS, LAFAN, Motion-X++, and Bones-Seed. The quality evaluation results are compared in Figure 3.
Figure 2
Figure 3
Figure 4
Figure 4 illustrates the motion space diversity / coverage. To achieve a fair comparison, all datasets were flattened into temporal motion tensors and fed into an encoder–decoder network for standard t-SNE representation learning. The learned latent features were then projected into a 2D latent space. The results show that HiPHI-MOV almost fully occupies the latent space, while existing datasets appear as subsets within the HiPHI-MOV distribution. This demonstrates the broad motion coverage of HiPHI-MOV, capturing both common motion patterns and distinctive local structures.
How to use HiPHI-MOV
HiPHI-MOV is well suited for motion tracking based locomotion or loco-manipulation learning. Such approaches leverage high-quality and diverse human motion trajectories as reference signals, construct imitation-based reward functions, and perform reinforcement learning (RL) in physics simulation. Scaling up this type of data enables generalization across the human motion space, with applications including whole-body teleoperation and terrain-adaptive loco-manipulation.
To validate the practical trainability of HiPHI-MOV, we established a closed-loop data training pipeline, including cross-embodiment retargeting, simulation-based RL training, sim-to-sim evaluation, and sim-to-real deployment. We further conducted preliminary scaling law validation to evaluate the effect of increasing dataset size on model performance. Video 2 summarizes the data utilization pipeline and shows results of our data and model validation, ensuring the quality and practical trainability of the dataset.
Video 2
The HiPHI-OM Data
Introduction
The HiPHI-OM Dataset is a human-centric, high-fidelity, omni-modal repository purpose-built for dexterous manipulation. It includes full-body and fine-grained hand motion, precise mesh tracking of interacting objects, hand-level tactile sensing, egocentric and sideview RGB-D streams. Leveraging tightly synchronized, high-precision sensor arrays, HiPHI-OM delivers ground-truth-level embodied data. All recordings are conducted by trained actors within dedicated data acquisition pods. We construct a script-generation framework based on the combinatorial space of hand-related manipulation primitives × object assets × scene constraints. There is an example shown below, and more instances can be found on the webpage.
Video 3
Quality Assessment
The entire data acquisition pipeline is captured under a hybrid optical–inertial motion capture system, where the body, fingers, object meshes, and camera extrinsics are all tracked using optical-grade markers. All marker trajectories are maintained within sub-millimeter spatial tracking error throughout the recording process. To our knowledge, no existing dataset provides such precise multimodal dexterous manipulation data.
How to use HiPHI-OM
HiPHI-OM supports multiple possible research directions which include, but are not limited to:
Video 4
The ITW Data
Introduction
The ITW dataset is a human-centric, life-scale, open-world multimodal corpus of stochastic real-world scenarios for advancing humanoid robotics and embodied intelligence. It includes sparse-body motion sensing from inertial or magnetic straps, egocentric RGB-D vision, audio, and optional sideview RGB-D data. Collected in unconstrained environments, ITW captures ecologically valid human behaviors and interaction dynamics under natural environmental variability. By incorporating high-variance noise and long-tail edge cases into the training distribution, ITW promotes robust generalization from laboratory settings to industrial deployment. When combined with the HiPHI datasets, it forms a cross-domain embodied corpus spanning diverse operational conditions and sensory modalities. ITW instances can be found on the webpage.
Data Enhancement
For raw ITW data, we leverage a multimodal model pretrained on a mixture of HiPHI datasets and egocentric vision and sparse body sensing from ITW to reconstruct wrist and hand motion, producing hand end-effector trajectories as action labels for ITW. We also use a portion of ITW data captured with sideview RGB-D for 4D full-body scene reconstruction. Some reconstruction results across modalities are shown in Video 5. The augmented data can be directly used to pretrain VLA or world models.
Video 5
Mixture of All
The standard format and detailed instructions of each data type are provided on ModalityNet Technical Specification v1.0. The three datasets are designed for joint use. Their integration is critical for scaling embodied AI models. A closely aligned recent advance is EgoScale [4] by NVIDIA. Additionally, HiPHI-MOV and HiPHI-OM support training full-body loco-manipulation control models, analogous to System 0 in HELIX 02 by Figure AI. Meanwhile, HiPHI-OM and ITW facilitate learning physical commonsense and multimodal understanding, analogous to System 1 and System 2 in HELIX 02.
Further validation results on data acquisition and utilization will be released in future updates. We aim to advance the field through rigorous data acquisition methodology, principled modality definition, and empirical validation of data effectiveness, delivering datasets with high fidelity, comprehensive modality coverage, and scalable volume.
If you are interested in these datasets and collaboration, please feel free to contact us.
References
[1] Baker C. F., Fillmore C. J., Lowe J. B. The Berkeley FrameNet Project. The 17th International Conference on Computational Linguistics, 1998.
[2] Luo Z., Yuan Y., Wang T., et al. SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control. arXiv preprint arXiv:2511.07820, 2025.
[3] Yang L., Huang X., Wu Z., et al. OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction. arXiv preprint arXiv:2509.26633, 2025.
[4] Zheng R., Niu D., Xie Y., et al. EgoScale: Scaling Dexterous Manipulation with Diverse Egocentric Human Data. arXiv preprint arXiv:2602.16710, 2026.
Citation
@article{nr2026modalitynet,
title={ModalityNet: The Art of Modalities in Human-Centric Data},
author={Noitom Robotics Team},
journal={Noitom Robotics Blog},
year={2026},
note={https://noitomrobotics.com/tech-blog/},
}